
THE AUTHOR:
Ayushman Dash, Head of Data and AI at Jus Mundi
Key Takeaways
- Standard embedding models fail arbitration professionals because they match text, not legal intent
- Jus AI Tenet is Jus Mundi’s proprietary LLM stack powering Jus AI. Jus AI Tenet v5 is a custom embedding model trained specifically on legal and arbitration data, encoding 15+ metadata fields per document
- Better retrieval means the entire AI workflow improves: less noise, more reasoning, stronger citations
- The results are measurable: 46% reduction in token consumption, 30% reduction in margin of error, failure rate cut in half
- This is the new retrieval foundation that every future Jus AI capability will be built on
The quality of any AI-powered legal research tool depends, above all, on one thing: whether it retrieves the right document in the first place.
This sounds deceptively simple. In practice, it is the hardest problem in legal AI to solve well, and the one most frequently glossed over in favor of more visible improvements to interface or output. At Jus Mundi, we have spent the past year working on this foundational challenge. The result is Jus AI Tenet, our proprietary intelligence stack built specifically for legal and arbitration research. Today, we are releasing its first component: Jus AI Tenet v5, a custom embedding model designed from the ground up to understand how legal professionals think and what they actually need when they search.
The Limits of General-Purpose Models
To understand why we built this, it helps to understand how standard embedding models work and where they fail.
When a user submits a query, an embedding model converts it into a numerical representation and then identifies the paragraphs in the database whose representations are closest in meaning. For general-purpose applications, this approach is highly effective. For arbitration research, it breaks down in ways that are both predictable and consequential.
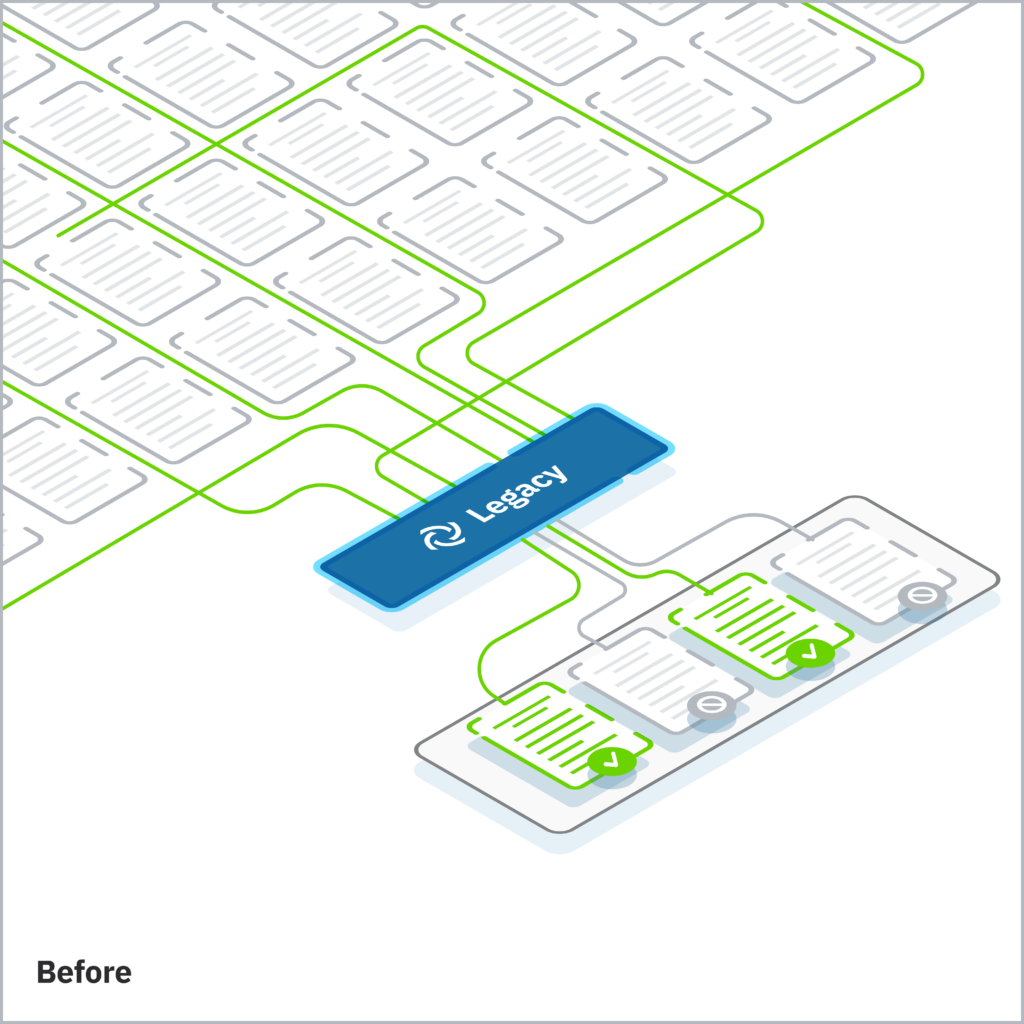
Legal queries are not simply about the words they contain. They depend heavily on the context that surrounds a document: the name of the case, the composition of the tribunal, the seat of arbitration, the applicable treaty or institutional rules. That contextual information almost never appears in the specific paragraph that contains the reasoning a practitioner needs. A passage from an award analyzing the tribunal’s approach to consent to arbitration will rarely repeat the case name, the parties, or the jurisdictional basis. Standard models, blind to this surrounding context, retrieve based on surface text alone.
Consider a query such as: “Analyze the tribunal’s reasoning in Dallah regarding arbitrability and consent to arbitration. Compare the approach taken by French courts generally, as well as the UK Supreme Court.”
A standard model will surface paragraphs that mention “consent” and “arbitration.” Most of them will be irrelevant to the precise legal question being asked. It is the equivalent of asking a librarian to find a specific ruling from a French court, but the librarian cannot see the title, the author, the year, or the jurisdiction of any book. They can only read random paragraphs inside. They hand you 100 results, 90 of which have nothing to do with your actual research need.
This is not a marginal imprecision. In arbitration, where the applicable instrument, the specific party, or the procedural phase can change the legal outcome entirely, retrieval errors compound at every step of the research process.
What Jus AI Tenet v5 Does Differently
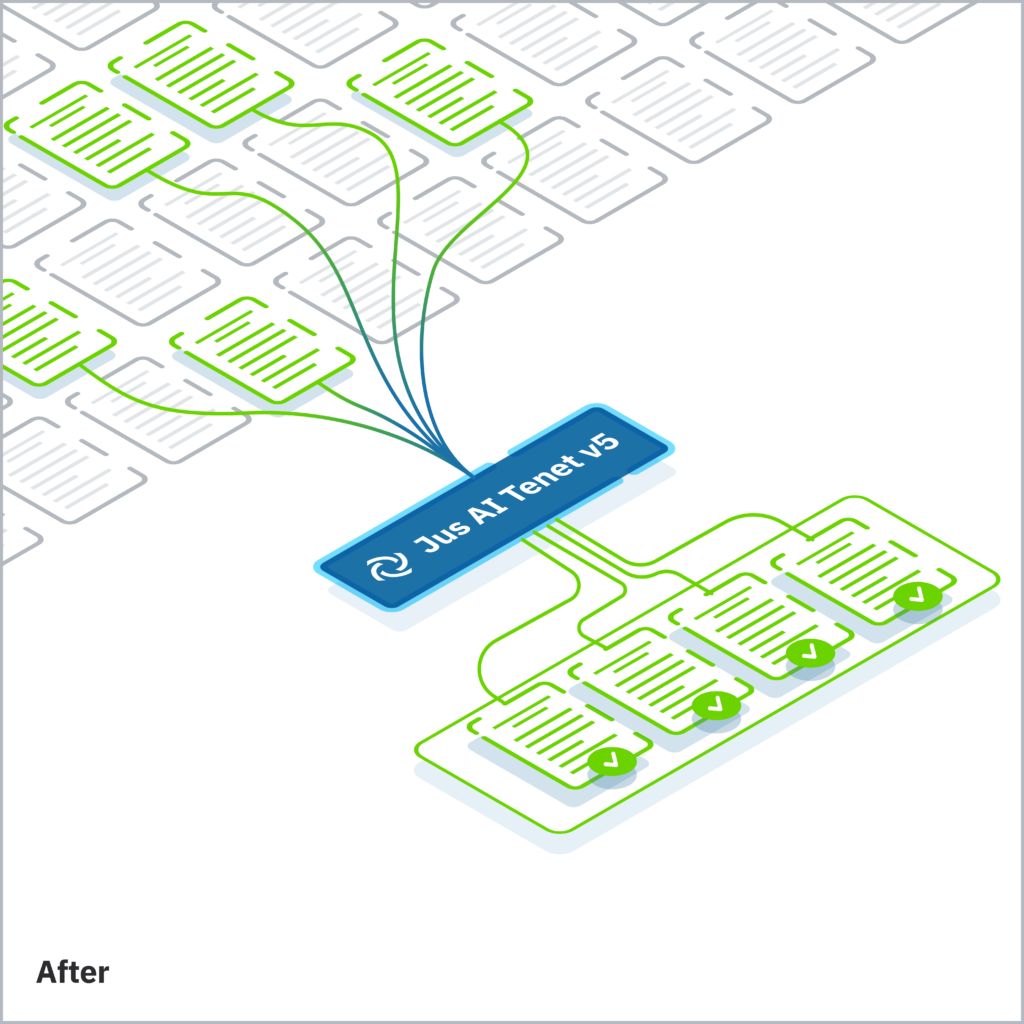
Jus AI Tenet v5 was built to solve this problem at its root. For every paragraph in our database, the model encodes more than 15 distinct metadata fields alongside the full context of the document it belongs to. Relevancy is calculated not against the surface text of the user’s query, but against their holistic legal intent.
This distinction matters enormously in practice. Arbitration documents are structurally repetitive: procedural rules, treaty language, and boilerplate formulations appear across thousands of awards and decisions. A model that cannot distinguish which procedural context, which treaty provision, or which tribunal’s reasoning is actually responsive to a given query will consistently retrieve authoritative-looking but ultimately unhelpful material.
Building a model capable of making these distinctions required sustained engineering effort across three interconnected challenges. First, assembling and validating high-quality training signals in a domain where expert review is costly and time-consuming. Second, accelerating the iteration cycle so we could move quickly from early prototypes to a stable fifth version, without compromising quality. Third, and most fundamentally, realigning how the model measures relevance: teaching it to map document passages to a user’s legal intent, rather than merely matching patterns in the query text.
A Cascade of Improvements
The impact of better retrieval does not stay contained to the retrieval layer. It propagates through every subsequent step of the AI workflow.
In a standard system, the imprecision of the retrieval model forces a compensating strategy: retrieve more, and rely on the large language model to filter out the noise. A query that should require 100 paragraphs might require 300 just to ensure the relevant material is included. But every large language model operates within a finite context window, and every token spent on irrelevant material is a token unavailable for legal reasoning.
Our testing demonstrates the consequences of fixing this at the source. Retrieving 100 paragraphs with Jus AI Tenet v5 yields more relevant, usable information than retrieving 300 paragraphs with a general-purpose model. The downstream effects are measurable: a 46% reduction in overall token consumption, a 30% reduction in margin of error in our most comprehensive research mode, and a failure rate cut in half in our rapid-response mode. Because the model is no longer consuming its processing capacity on noise elimination, its reasoning is more faithful, its citations more precise, and its outputs more grounded in what the sources actually say.
What Practitioners Will Notice
For arbitration professionals using Jus AI before and after this release, the difference is most visible in three areas.
The assistant now handles significantly more nuanced, multi-dimensional queries without requiring reformulation. Questions that reference specific legal angles, parties, or procedural phases, including the kind of complex, multi-layered research questions that experienced practitioners actually ask, are addressed with greater precision from the first response.
Sources are more targeted from the outset. The assistant breaks queries into granular research tasks and applies enhanced retrieval across each of them, returning authorities that are more tightly focused on the precise legal question at issue. This reduces the manual verification burden that has historically accompanied AI-assisted research, and shortens the path from query to actionable analysis.
Citations have become more precise. They now link with greater accuracy to the specific passages that support each statement in the response, making the assistant’s reasoning easier to trace and verify against primary sources. In arbitration practice, where the strength of a position often depends on the exactness of its authority, this is not a marginal improvement. It is a material change in how much the output can be trusted and used.
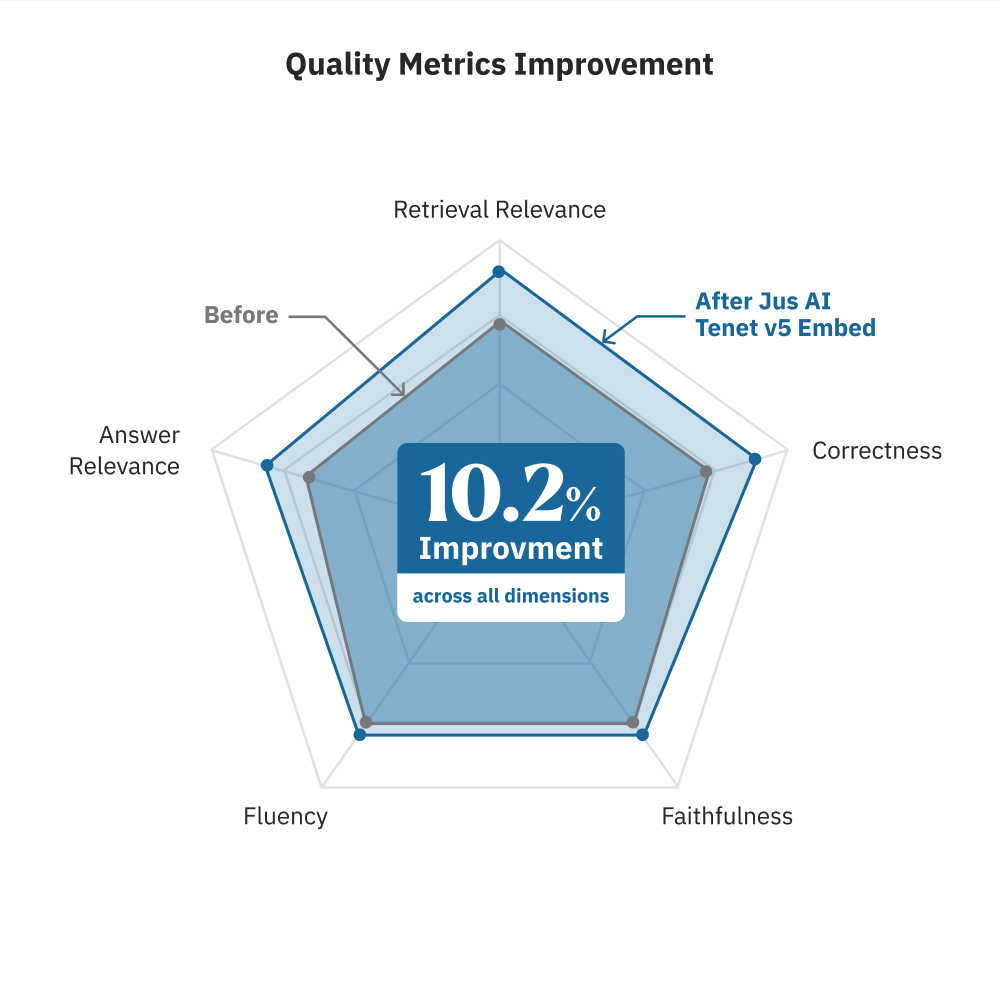
Benchmarked against our previous embedding system, which scored 79.2% across these metrics, Jus AI Tenet v5 achieves a 10.2% average improvement (89.4%) across five quality dimensions: Retrieval Relevance, Correctness, Faithfulness to Sources, Fluency, and Answer Relevance. In AI development, that is a substantial leap. It reflects not incremental tuning but a purpose-built model doing what general-purpose systems cannot: retrieving with legal intent, not just textual similarity.
What Comes Next
Jus AI Tenet v5 solves the retrieval layer. The next step is the reasoning layer.
We are currently developing a full-stack language model trained specifically on arbitration. Not a general-purpose model adapted for legal use, but a model built from the ground up on arbitration data, designed to handle the tasks that matter to practitioners: document structuring, metadata extraction, legal reasoning, and tool execution, in a single step, without the intermediate layers that current architectures depend on.
In practical terms, this means a model that operates across every level of our intelligence stack. The same model that structures an unstructured award during ingestion will be the model that answers a practitioner’s research query. The same model that extracts procedural metadata will be the one powering every agent we build. Smaller and more specialized than the general-purpose systems it replaces, it will be significantly more energy efficient and significantly more accurate on the tasks arbitration professionals actually need.
Future versions may not require retrieval augmentation at all. The model will carry enough arbitration knowledge to answer directly. We are not there yet. But Jus AI Tenet v5 is what makes that trajectory possible. It is the first layer of an intelligence stack that is being built, from the ground up, for one community and one purpose.
Jus AI Tenet v5 is live across Jus AI today. If you would like to learn more about what precision retrieval looks like in practice, we would be happy to walk you through it.



