
This year, Jus Mundi’s data science team decided to participate at SemEval 2023 [1], more specifically on Task 6 – B, “LegalEval: Understanding Legal Texts Legal Named Entity Recognition”. The goal of this task was to create a Named Entity Recognition system capable of detecting 14 types of legal named entities, such as Claimant, Judge, Witness, and Organizations, in Indian judgments.
What is Legal Named Entity Recognition?
Named Entity recognition, also known as NER, is a Natural Language Processing (NLP) task, that relies on tagging a word, or a group of them, with semantic labels, such as Location, Person, and Organization [2]. In the case of Legal NER, these entities can be those related to the parties, such as Claimant and Respondent, but also those more related to judgments, such as Judge, Lawyer, Witness, Provisions, and Statutes.

Figure 1: Examples of annotations for Legal Named Entity Recognition
About Jus Mundi’s Participation
Jus Mundi decided to participate in Task 6 – B using technologies that our team of Data Scientists has developed in-house to deal with similar problems within Jus Mundi data. Specifically, we built a Legal NER using machine learning, using an architecture called Frustratingly Easy Domain Adaptation [3] [4]. The goal of this architecture is to train a model where the knowledge between different collections of data is shared in order to create a robust NER system. We created this architecture using PyTorch, a well-known framework to create neural networks, and DeBERTa-V3, a language model trained by Microsoft and accessible through the HuggingFace platform. Moreover, Jus Mundi trained this model using the French super-calculator “Jean Zay”, through our project allocation 2022-AD011012667R1.
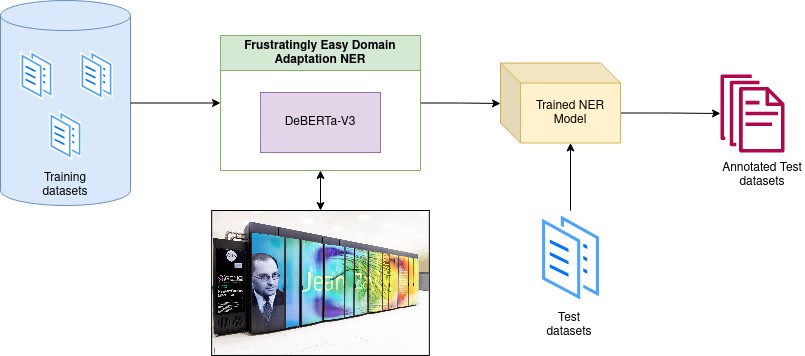
Figure 2: Simplified architecture of Jus Mundi’s participation at SemEval 2023.
The image of Jean Zay comes from [5]
Our team of Data Scientists reached the 4th place, out of of 17 participants from all around the world, with a score of 0.9007 out of 1.
If you want to know more about Jus Mundi’s participation, read our full article here.
Bio
Luis Adrián Cabrera-Diego is a Data Scientist at Jus Mundi. He has a Ph.D. in Computer Science from the University of Avignon and he is a Computer Engineer from the National Autonomous University of Mexico (UNAM). Before joining Jus Mundi, he worked on two European Projects Horizon 2020 as a postdoctorate, at Edge Hill University, U.K., and at the University of La Rochelle, France.
[1] SemEval is a series of research workshops that focus on natural language processing tasks. https://semeval.github.io/
[2] Li J, Sun A, Han J, Li C. A Survey on Deep Learning for Named Entity Recognition. IEEE Transactions on Knowledge and Data Engineering. 2020:1-1.
[3] Daum´e III H. Frustratingly Easy Domain Adaptation. In: Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics. Prague, Czech Republic: Association for Computational Linguistics; 2007. p. 256-63. Available from: https://www.aclweb.org/anthology/P07-1033.
[4] Cabrera-Diego LA, Moreno JG, Doucet A. Using a Frustratingly Easy Domain and Tagset Adaptation for Creating Slavic Named Entity Recognition Systems. In: Proceedings of the 8th Workshop on Balto-Slavic Natural Language Processing. Kiyv, Ukraine: Association for Computational Linguistics; 2021. p. 98-104. Available from: https://www.aclweb.org/ anthology/2021.bsnlp-1.12.
[5] Com-idris. Le supercalculateur Jean Zay de l’IDRIS; 2020. [Online; accessed July 24, 2023]. Available from: https://commons.wikimedia.org/wiki/ File:Le_supercalculateur_Jean_Zay_.jpg.


